Active Projects
These are projects that are very actively under development.
Academy
A framework for deploying agents across federated infrastructure.
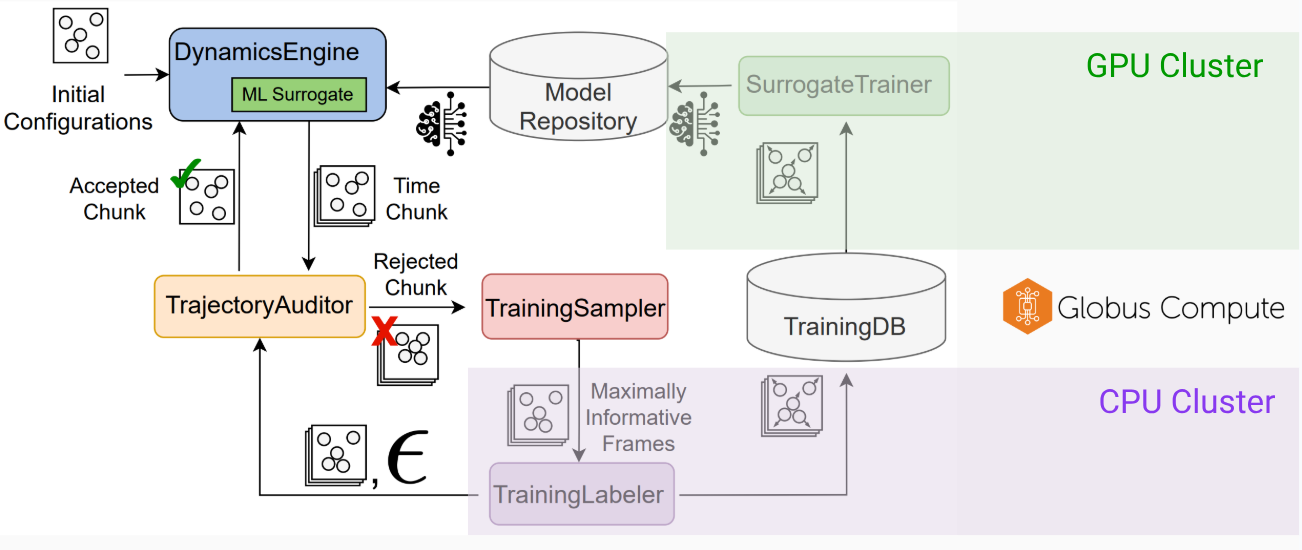
Cascade
Distributed on-the-fly learning for ML surrogates
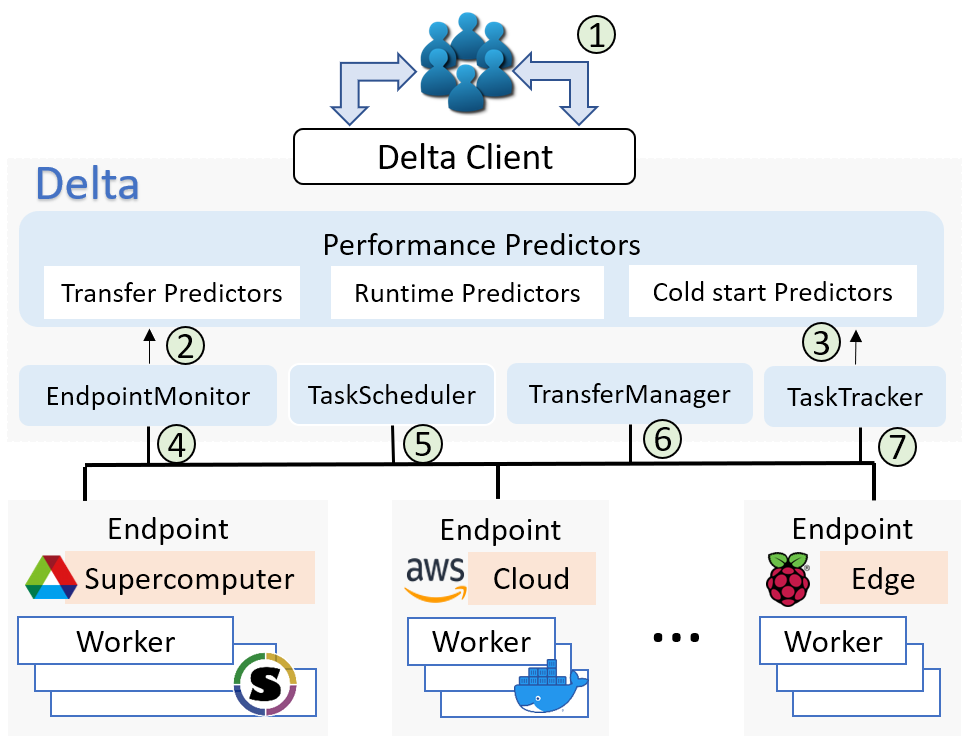
Cost-aware computing
Automating cost-aware profiling, prediction, and provisioning of cloud and HPC resources.

Colmena
Machine Learning-Based Steering of Ensemble Simulations
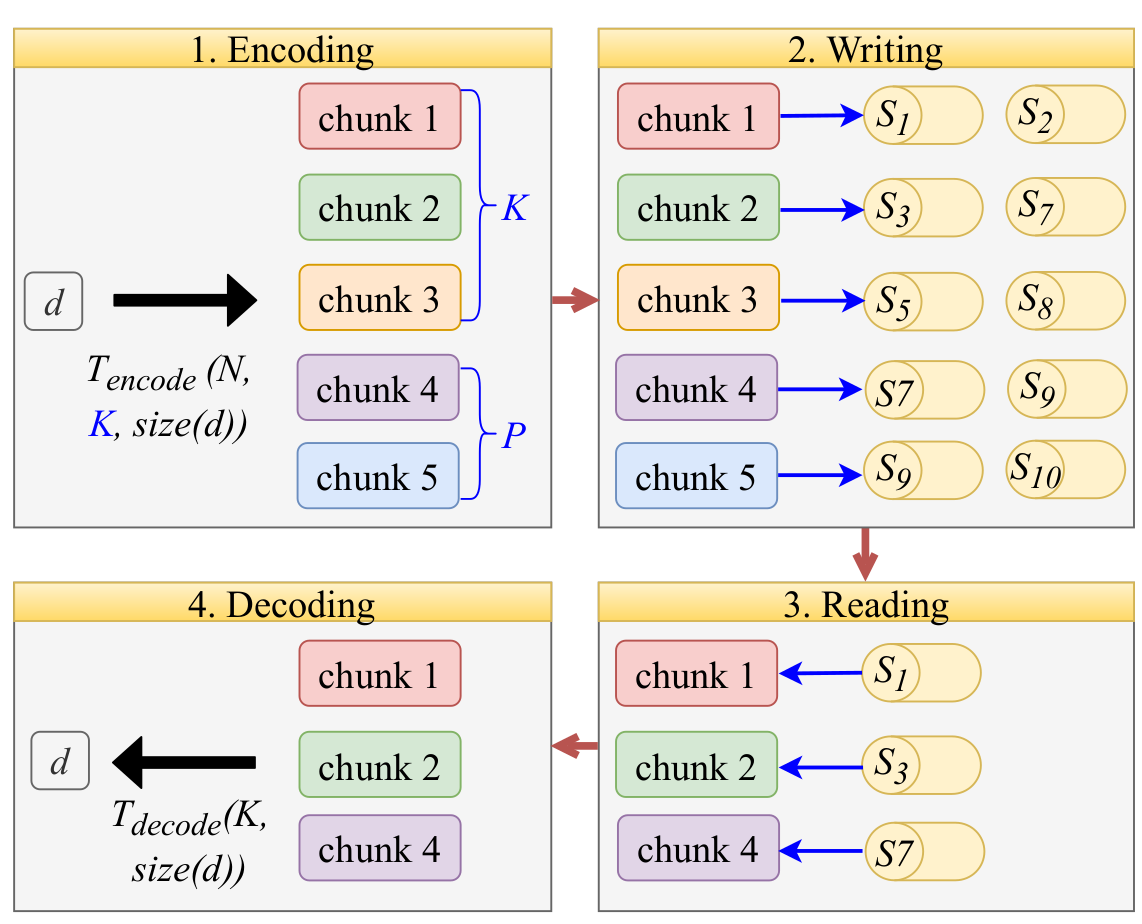
D-Rex
Algorithms and models for fast, reliable data storage using erasure coding with heterogeneous storage nodes

Flight
Hierarchical Federated Learning across the Computing Continuum.

Flows
We are developing methods to automate the scientific data lifecycle.

Foundry
An open source machine learning platform for scientists
funcX
funcX is a Function as a Service platform for scientific computing.
Garden
Garden turns researchers' AI models into citable APIs that run on scientific computing infrastructure.
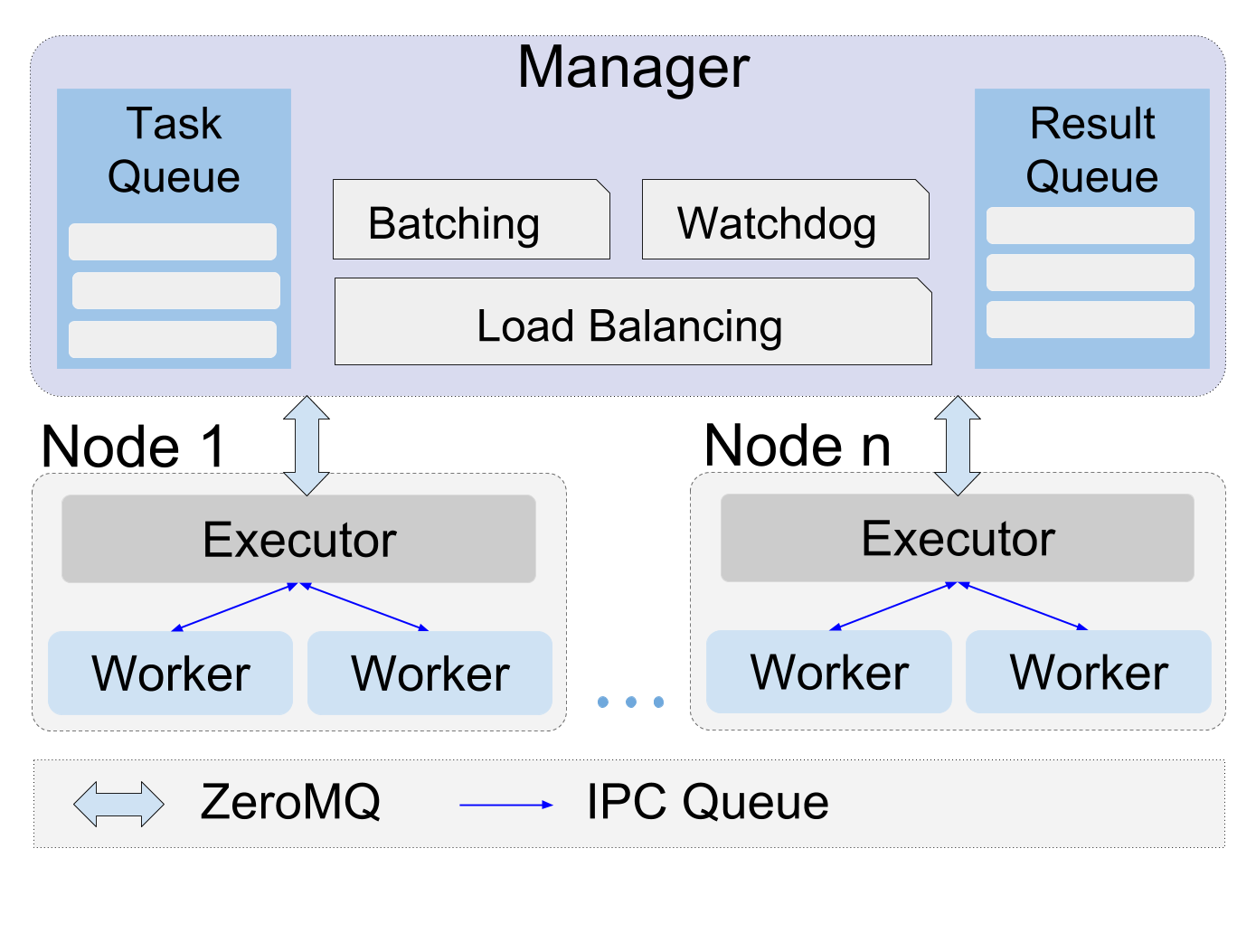
Gladier
Globus Automation for Data-Intensive Experimental Research

GLassBox
Interpretability Tools for Understanding ML models
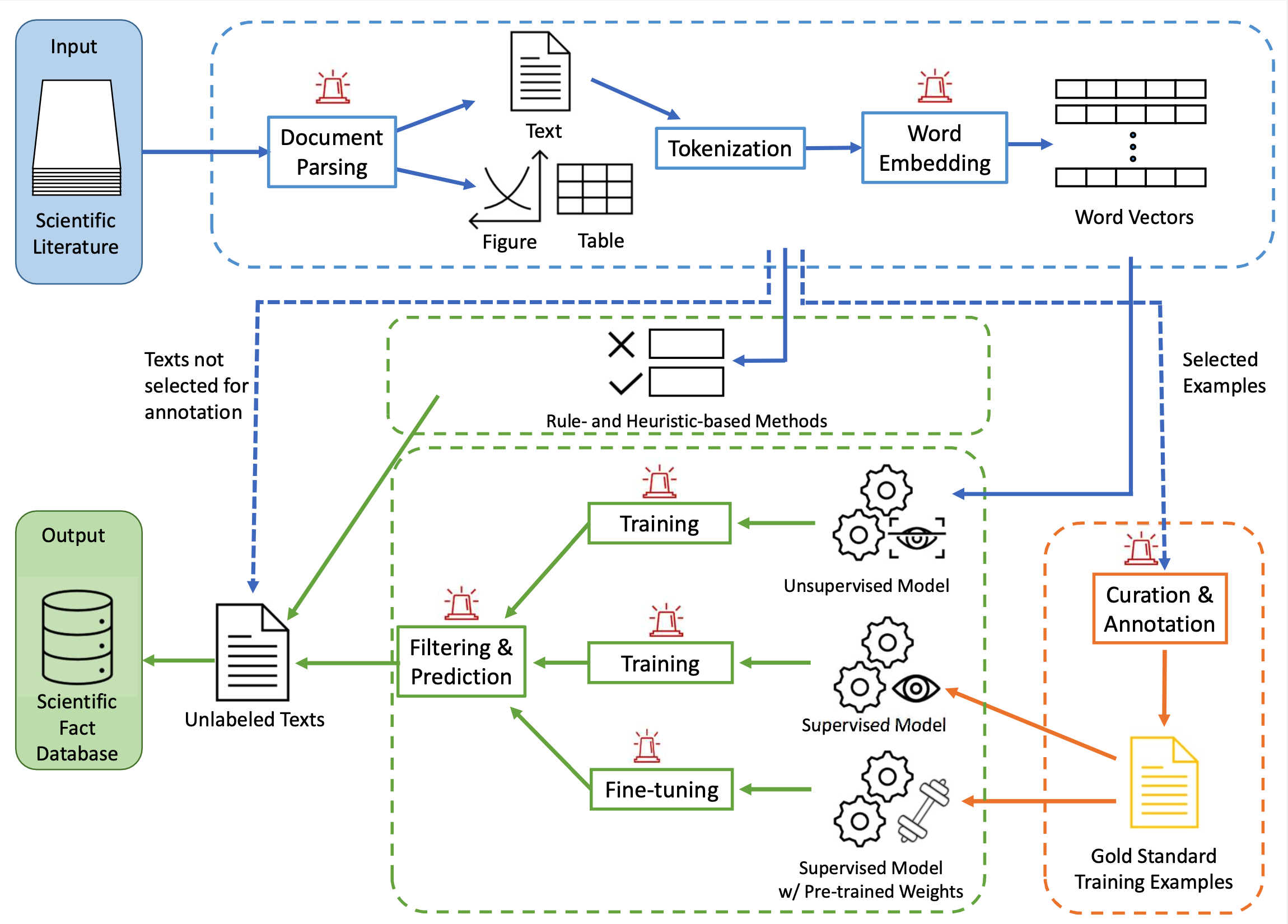
Scientific Language Modeling and Information Extraction
Data mining from literature with a foundational science-focused language model

LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Memory-efficient, extreme-scale document deduplication using Bloom filters
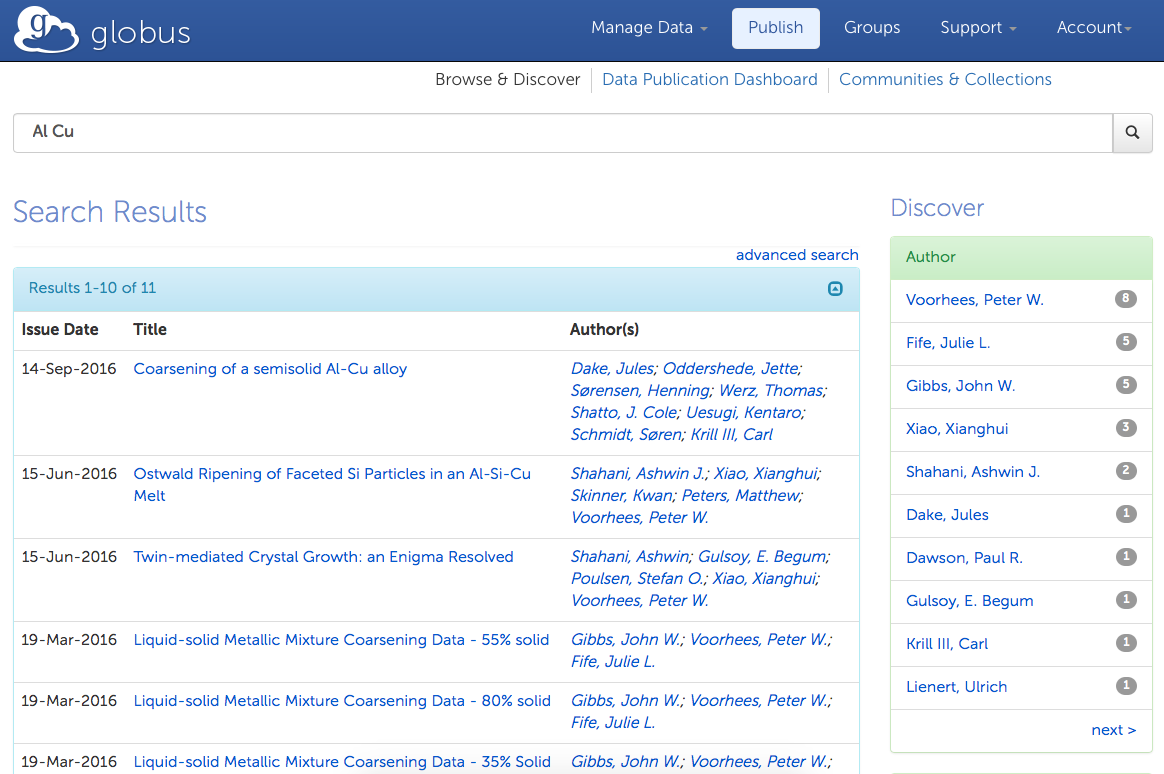
The Materials Data Facility
We are creating data services to help materials scientists publish and discover data

MFANN
Mutivariate Functional Approximation through Neural Networks

MPI-LLM
An MPI-based multi-model serving system for HPC with fast model switching.

BRISKNet
Breast Rapid Imaging via Self-Supervised Kinetics

Octopus Event Fabric
Cloud-to-edge event fabric that handles millions of events securely at scale.
Parsl
Parallel programming library for Python
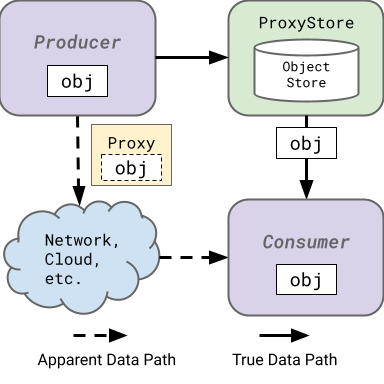
ProxyStore
Facilitate efficient data flow management in distributed Python applications.
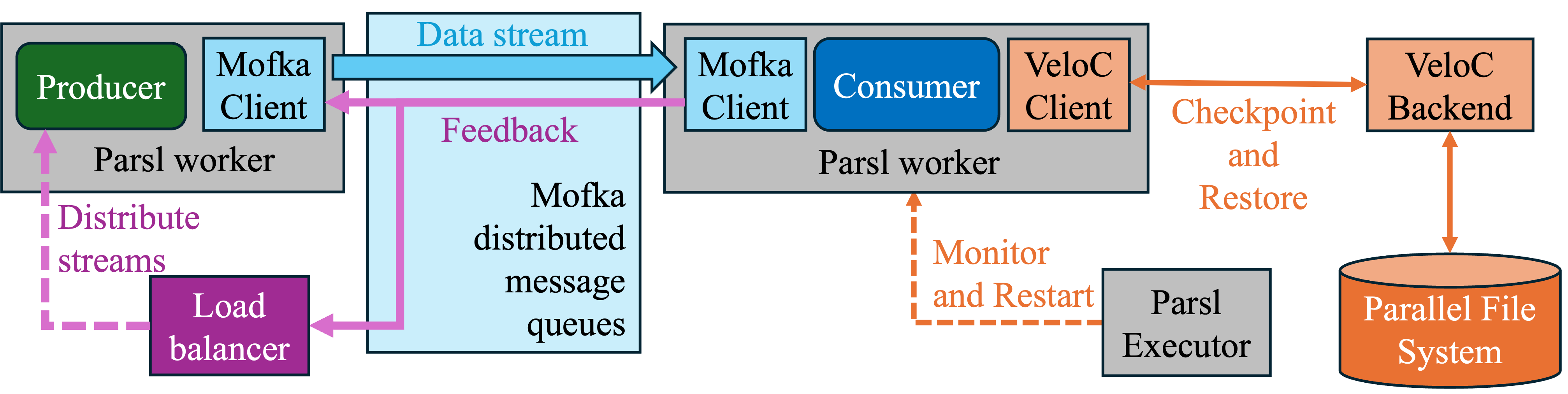
Resilient Solutions
Resilience Solutions for Large-scale Computing
Federated Query Routing
Adaptive routing for scalable scientific discovery
Streams
Secure, High-performance Memory-to-Memory Data Streaming

SZ3 Compression
We develop a series of prediction-based lossy compression algorithms for scientific simulations.
WaterMark
A benchmark of temporal AI models for water level prediction

Whole Tale
Whole Tale is a cloud-hosted platform for conducting and sharing reproducible science

XTask
Optimizing Fine-Grained Parallelism on OpenMP with NUMA awareness.
Other Projects
These are projects that are not currently being actively developed but may or may not still be used to support above active projects.
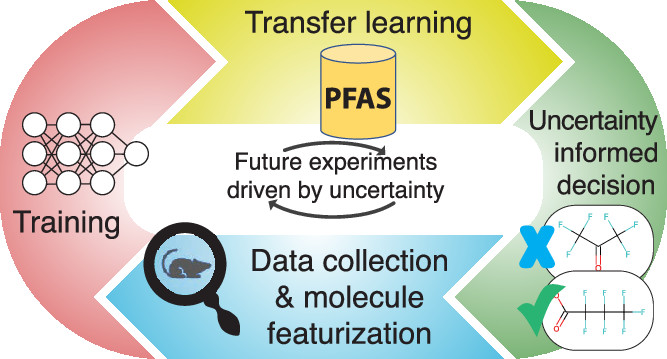
AI4PFAS
Deep learning workflow and dataset for toxicity prediction.
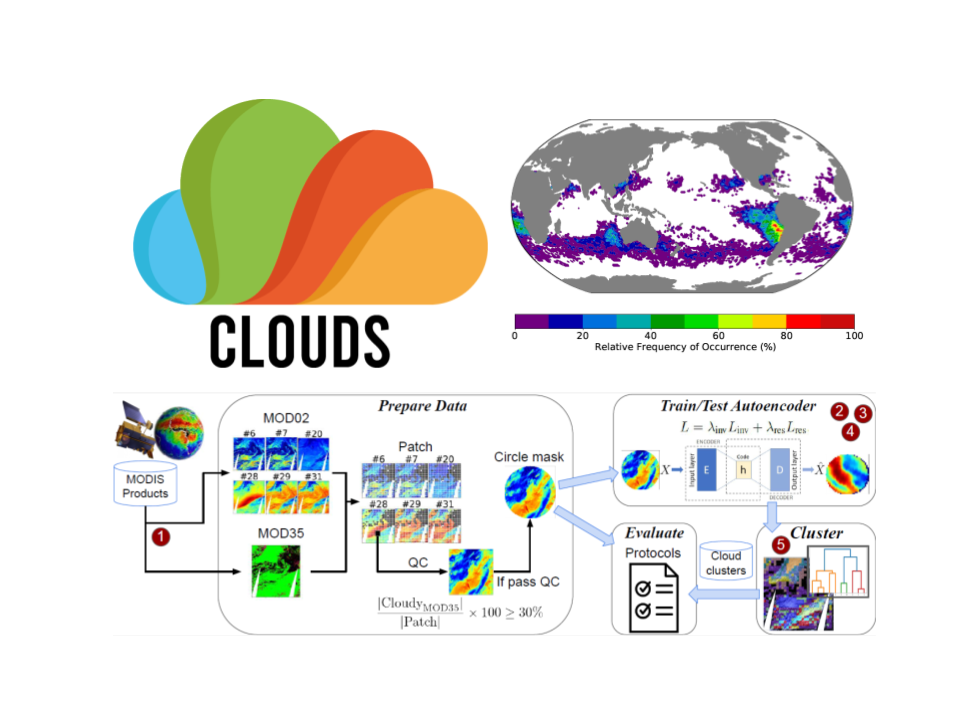
Clouds
Self-supervised data-driven methods for the application on big satellite clouds imagery

CODAR
We develop methods for online data analysis and reduction on exascale computers
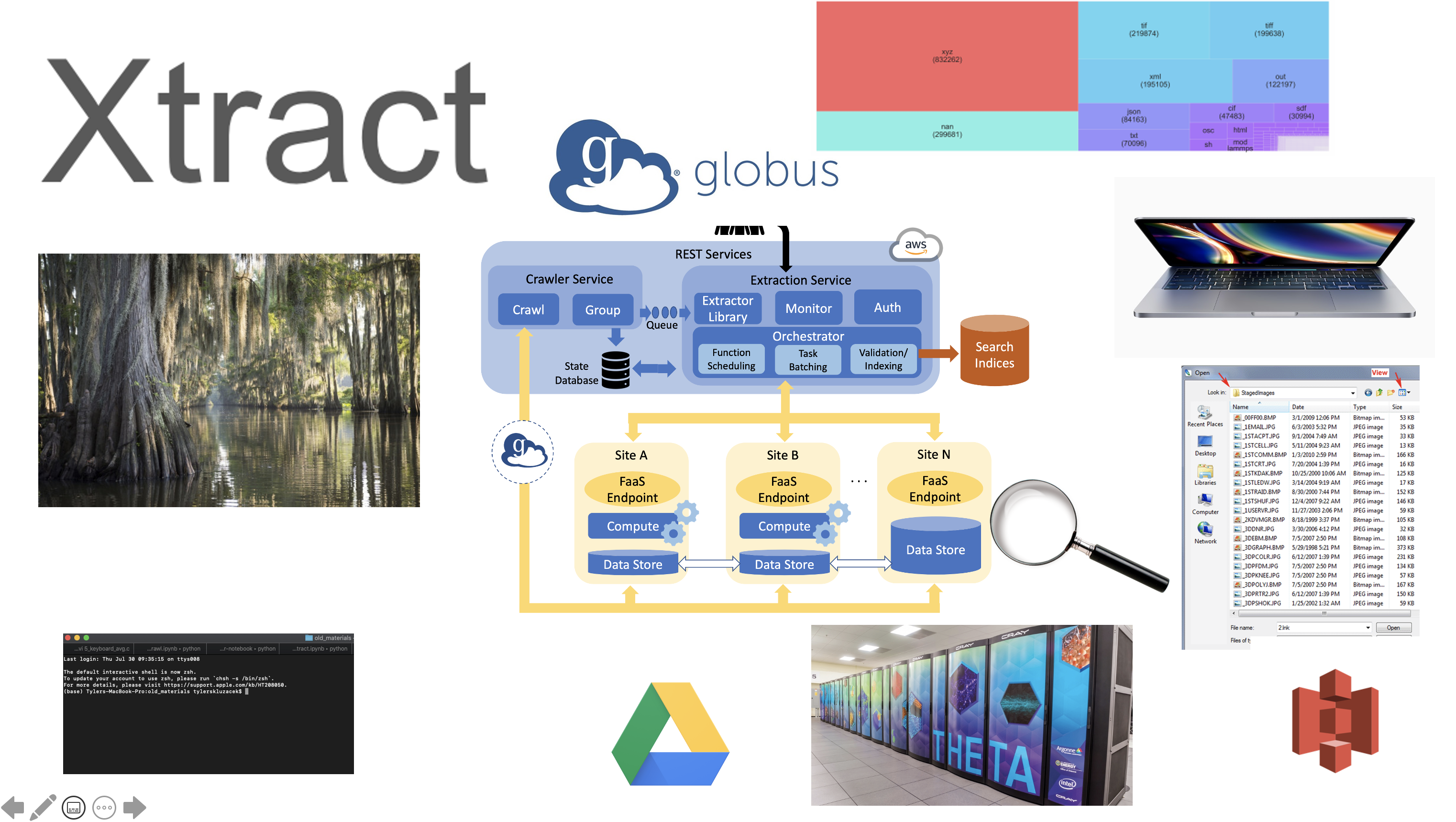
Xtract
Metadata Extraction for Everyone
Data and Learning Hub for Science (DLHub)
A simple way to find, share, publish, and run machine learning models and discover training data for science
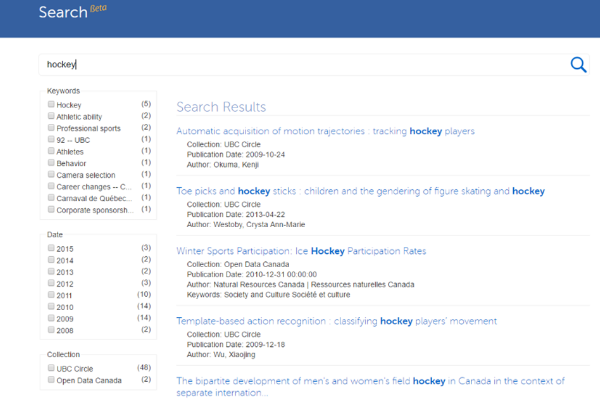
Globus Search
We are developing methods to index large amounts of scientific data distributed over heterogeneous storage systems
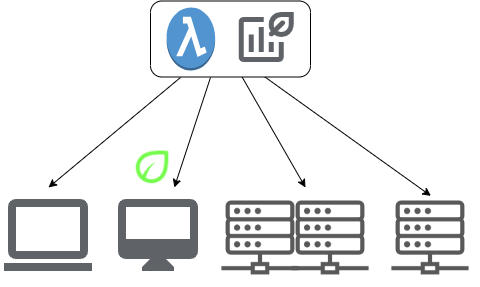
GreenFaaS
A monitoring and scheduling framework to find the most energy-efficient endpoints for your application.
KAISA: Scalable Second-Order Deep Neural Network Training
KAISA is a novel distributed framework for training large models with K-FAC at scale.