Links
Xtract
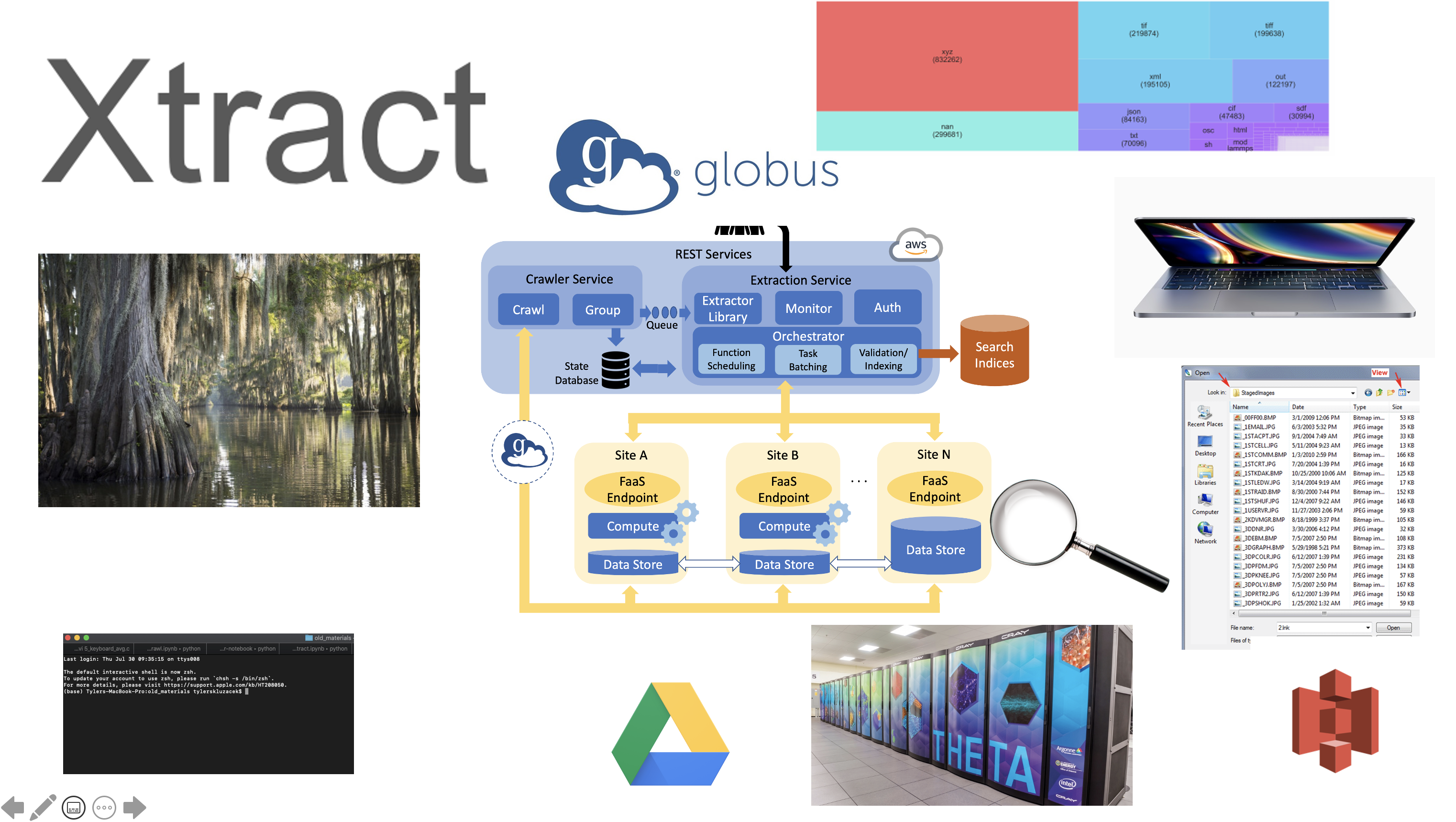
The rapid generation of data from distributed IoT devices, scientific instruments, and compute clusters presents unique data management challenges. The influx of large, heterogeneous, and complex data causes repositories to become siloed or generally unsearchable—both problems not currently well-addressed by distributed file systems. To this end, we at Globus Labs are actively building Xtract, a serverless middleware that leverages FaaS in order to extract metadata from files spread across heterogeneous edge computing resources. We’re currently studying how Xtract can automatically construct file extraction workflows subject to users’ cost, time, and compute allocation constraints. To this end, Xtract enables the creation of a searchable centralized index across distributed data collections.
In our most recent paper “A Serverless Framework for Automated Bulk Metadata Extraction”, we developed scalable, decentralized metadata extraction workflows for data stored in the Materials Data Facility at Argonne National Lab. We showed that we could scalably process over 2.2 million files in under 6 hours by using supercomputing resources.
Publications
- A Serverless Framework for Automated Bulk Metadata Extraction (link coming soon!)
- Serverless Workflows for Indexing Large Scientific Data. WoSC, 2019.
- Skluma: A Statistical Learning Pipeline for Taming Unkempt Data Repositories. SSDBM, 2017.
Funding and Acknowledgements
We gratefully acknowledge the computing resources provided and operated by the Research Computing Center at the University of Chicago; and the Joint Laboratory for System Evaluation (JLSE) and the Advanced Leadership Computing Facility (ALCF) at Argonne National Laboratory. This work was performed under financial award 70NANB19H005 from the U.S. Dept. of Commerce, National Institute of Standards and Technology as part of the Center for Hierarchical Materials Design (CHiMaD). This work is supported in part by the National Science Foundation under Grant No. 2004894.