Links
Tags
#Machine Learning #Cloud and Edge Computing #HPC #Stream Processing #Real-time #Fault Tolerance #CheckpointResilient Solutions
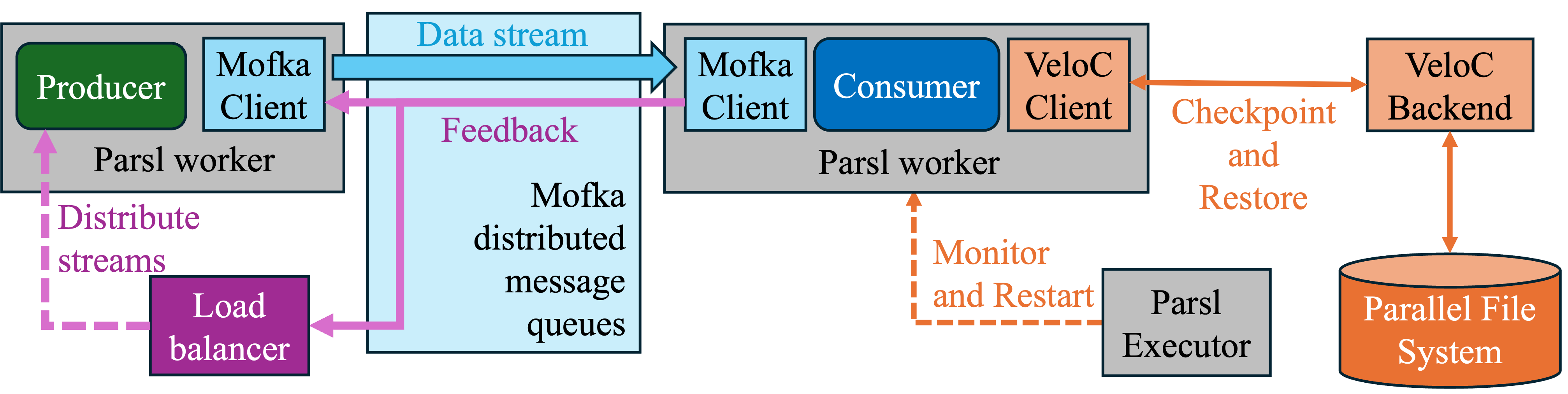
Modern scientific and data-intensive applications operate at unprecedented scale to meet rapidly growing data volumes and computational demands. At these scales, failures and performance variability are no longer rare events but normal operating conditions. This project develops resilience solutions for this new challenge, enabling applications to run reliably across failure- and anomaly-prone large-scale infrastructures–from supercomputers to geographically distributed streaming environments–as if operating in a failure-free environment. Our solutions include (i) a non-blocking, asynchronous checkpointing mechanism that minimizes recovery cost while introducing negligible overhead during failure-free execution, and (ii) an adaptive dynamic load-balancing strategy that mitigates performance anomalies and stragglers by continuously redistributing work based on observed processing capability and progress. Our solutions reduce the impact of failures on large-scale tomographic reconstruction workflows by up to 500x and enable scientific streaming applications to meet real-time deadlines across a wide range of failure rates and performance anomalies.
Publications
- H.D. Nguyen, T. Bicer, B. Nicolae, R. Kettimuthu, E.A. Huerta, and I.T. Foster: Resilient execution of distributed X-ray image analysis workflows. Frontiers in High Performance Computing 3 (2025)
Funding and Acknowledgements
This work is supported by the U.S. Department of Energy (DOE) under Contract No. DE-AC02-06CH11357, including funding from the Office of Advanced Scientific Computing Research (ASCR)’s Diaspora project and the Laboratory Directed Research.